Conjure: replacing library
dependencies with verified,
LLM-generated code
Every library dependency is attack surface. What if you could generate it away?
$ pip install conjure-llm
Abstract
Every library dependency is attack surface. A single compromised package in a dependency tree can affect thousands of downstream applications, as demonstrated by incidents like event-stream, ua-parser-js, and colors.js. We present Conjure, a system that eliminates library dependencies by generating self-contained function implementations from declarative YAML specifications using an embedded language model. Generated code is verified against the specification's examples, checked for security constraints via AST analysis, and cached in a content-addressed store. On ConjureEval-100, a benchmark of 100 specifications across 20 categories, a locally-running 9B parameter model achieves 87.9% pass@3 and 70.0% pass@1. Conjure's AST enforcement provably prevents 10 CWE vulnerability categories including code injection, embedded malicious code, and OS command injection. For the subset of functionality it replaces, Conjure eliminates the supply chain attack surface entirely. A historical analysis of 3,800 Python supply-chain incidents (2023–2025) finds that the attacks Conjure prevents account for up to 68% of all incidents, including every malicious-package attack targeting replaceable functionality. Across 5 real Python applications, Conjure reduces auditable code surface by up to 20×.
Lockfiles guard the door. The attacks use the door.
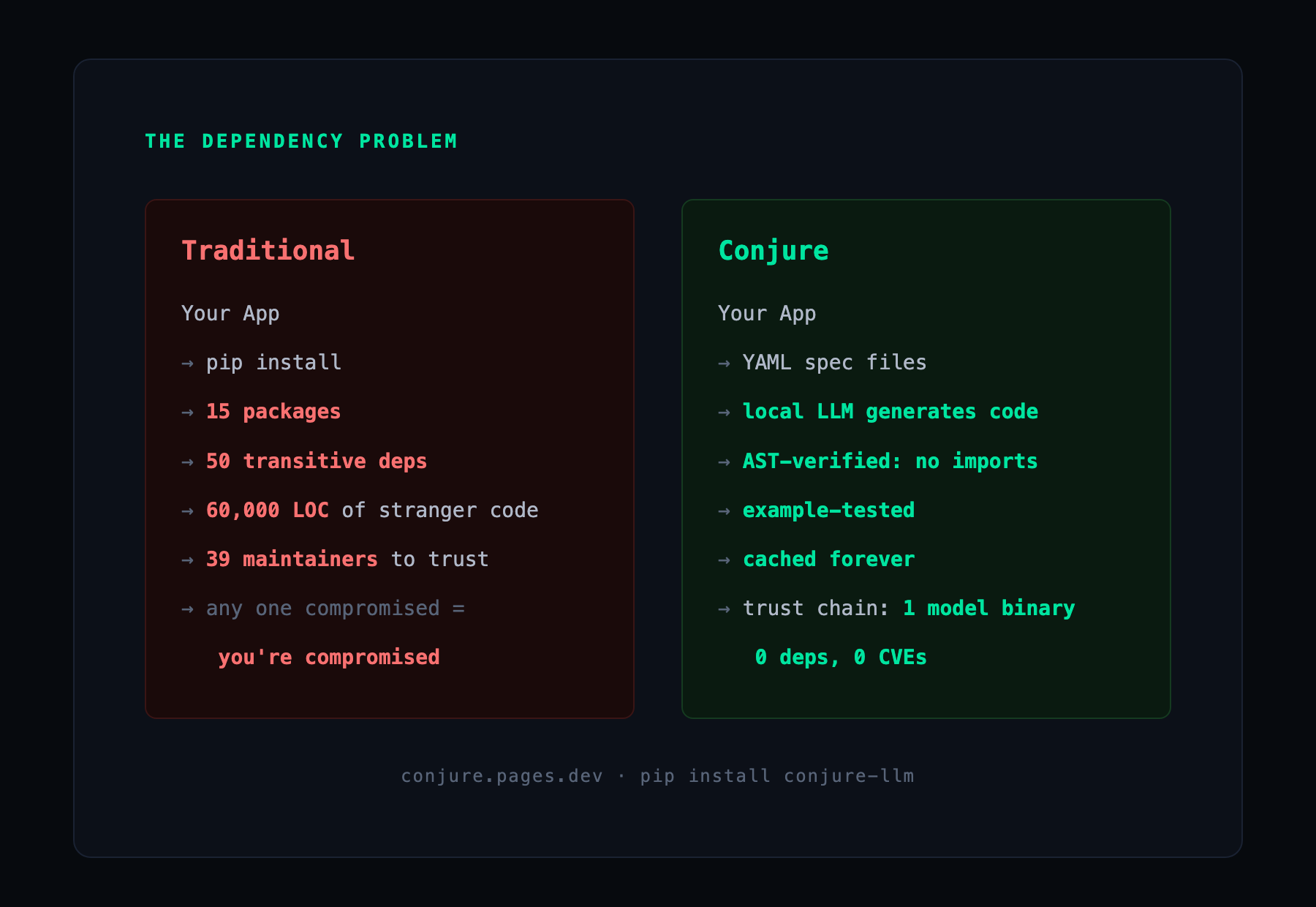
The average npm package implicitly trusts 79 third-party packages and 39 maintainers. Python is similar: a single pip install flask pulls in six transitive packages, each with its own maintainer and its own bad day waiting to happen.
When trust breaks, it breaks through the front door. In event-stream (2018) a new maintainer slipped cryptocurrency-stealing code into a package with two million weekly downloads, and it sat undetected for two months. In ua-parser-js (2021) a hijacked account pushed three poisoned versions in hours. In xz-utils (2024) a contributor spent two years building trust before planting a backdoor into the SSH authentication path of nearly every Linux server — caught only because one engineer noticed his logins ran 500ms slow.
Lockfiles, scanners, and signed builds all operate inside the package channel. They cannot stop an attack that uses that channel as the vector. So Conjure takes a different route: instead of guarding the dependency, remove it.
Embed the library compiler, like SQLite did
SQLite became one of the most-deployed pieces of software ever by embedding the database engine directly in the application process — no server, no network boundary, no operational complexity. The trade-offs are real but rarely matter, and an entire category of problems disappears.
Conjure applies the same principle to library code. You write a short YAML specification describing the function you need. An embedded language model running on your own machine generates a self-contained, import-free implementation. It is verified, then cached. The package registry, the dependency tree, and the supply chain are simply not in the picture.
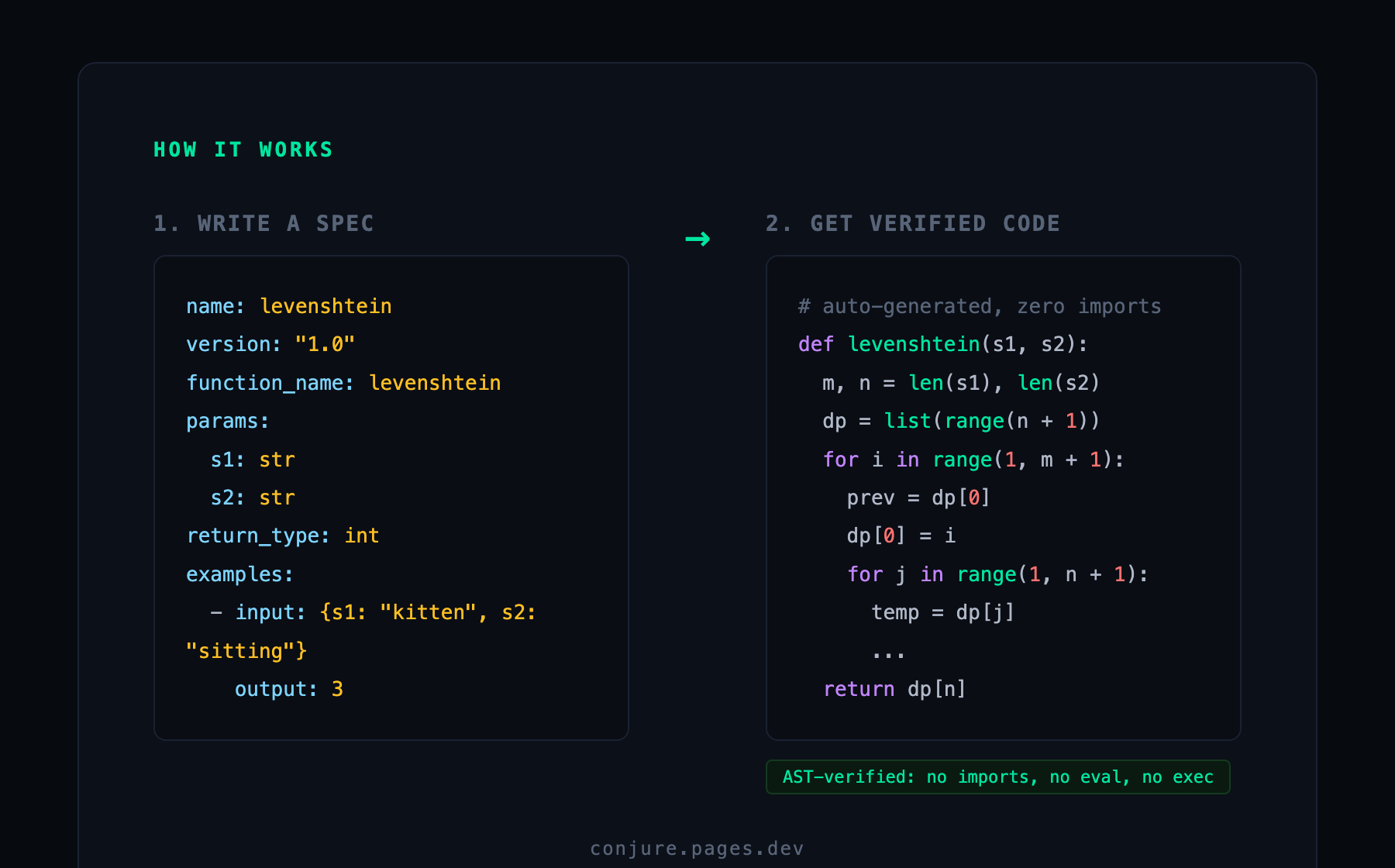
On a cache miss, Conjure builds a prompt from the spec, generates a candidate, and runs two gates: an AST walk and a sandboxed run of every example. On failure the exact error feeds back to the model for up to three attempts. That retry loop recovers 18 percentage points — from 70% on the first try to nearly 88%. The model usually knows how to fix its own mistake once told what broke. After verification, code is keyed on a hash of the spec and returns in ~0.3ms on subsequent calls.
“No imports” is structural, not a heuristic
Most secure-generation stories ask you to trust that the model behaved. Conjure does not. Before any function is cached, its syntax tree is walked and rejected if it contains an import, a call to eval / exec / compile / open, or any access to os / sys / subprocess / shutil. This is a structural invariant, not string-matching a payload can dodge: code that passes the check provably cannot reference those things.
No imports means no network, no filesystem, no shell. The worst a compromised model can do is return a wrong answer — which the example tests are there to catch.
The payoff against real incidents is concrete. A typosquatted package — there is no package to install. An account takeover — there is no maintainer in your trust chain. A poisoned transitive update — there are no transitive dependencies. Of ~3,800 Python supply-chain incidents (2023–2025), this approach neutralizes about 68%, including 100% of the 2,500+ malicious-package attacks.
87.9% pass@3, and up to 20× less code to audit
ConjureEval-100 maps 100 specifications to real PyPI functionality across 20 categories. A 9B model running locally — small enough to fit in roughly 5 GB on a laptop — reaches 70% on the first attempt and 88% with the retry loop.
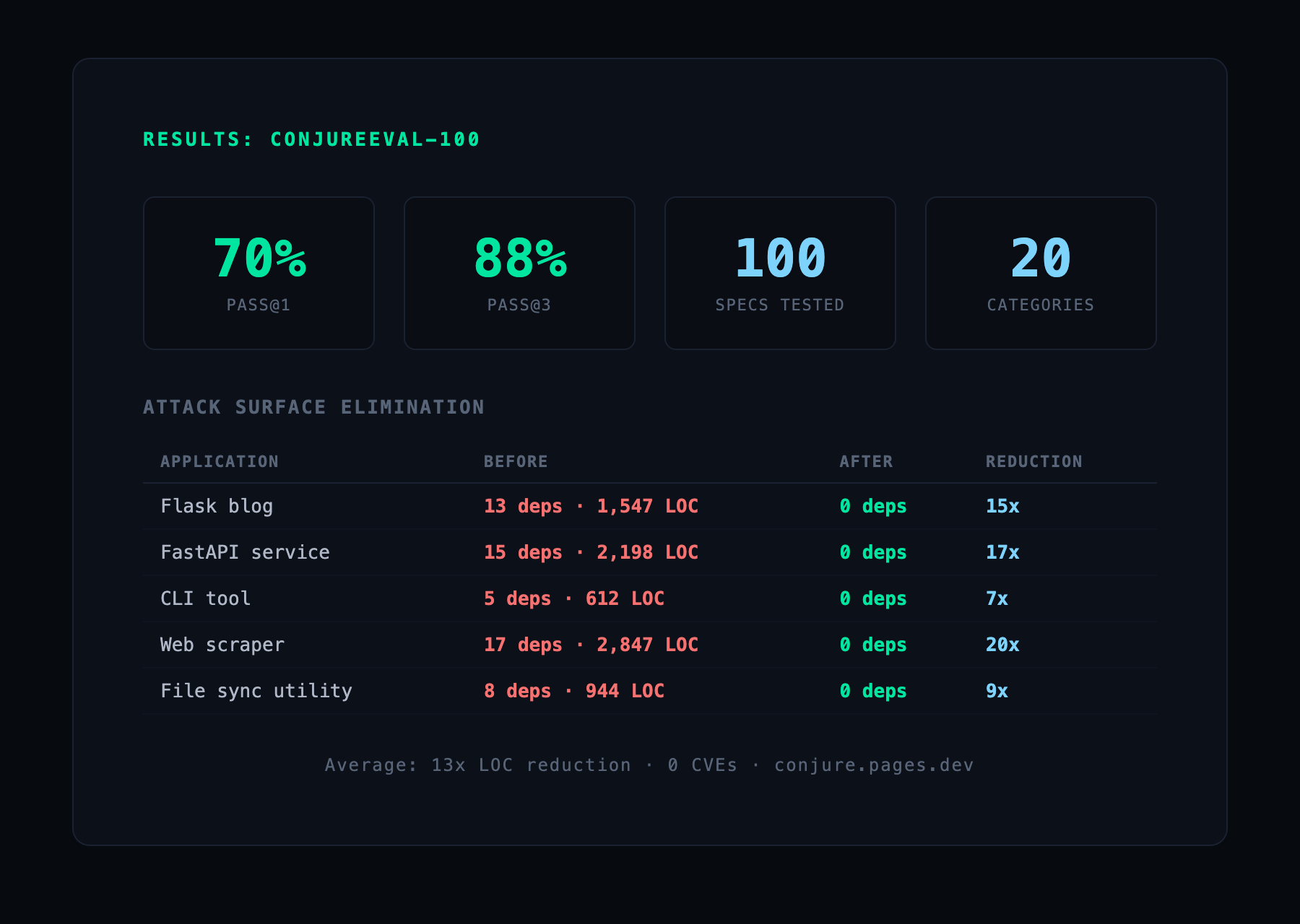
We measured five ordinary Python apps for how much dependency code Conjure could replace:
| Application | Dependencies | With Conjure | Reduction |
|---|---|---|---|
| Flask blog | 13 transitive | 0 | 15× |
| FastAPI service | 15 transitive | 0 | 17× |
| CLI data tool | 5 transitive | 0 | 6× |
| Web scraper | 17 transitive | 0 | 20× |
| File-sync utility | 8 transitive | 0 | 9× |
| Average: 13× reduction in auditable code surface | |||
What the paper establishes
- The Conjure system — zero-dependency code generation from YAML, with AST-enforced security constraints that provably prevent 10 CWE vulnerability categories.
- ConjureEval-100 — a 100-spec benchmark across 20 categories (70.0% pass@1, 87.9% pass@3), with a scaling analysis from 0.8B to 9B parameters.
- A supply-chain study — 3,800 historical Python incidents analyzed; 100% of malicious-package attacks eliminated; up to 20× attack-surface reduction across 5 real applications.
- A translation feasibility study — 40–52% of a typical application's imports are replaceable, with an end-to-end case study.
Where it falls down
The 9B model has a ceiling: SHA-256 (64 exact round constants) and full recursive-descent parsers remain beyond what it reliably generates — about 12% of specs land in this hard bucket. There is also a gap between passing examples and being correct: of functions that pass their example tests, ~60% also survive 30 random inputs, with failures clustered on edge cases rather than logic. The fix is mundane — add the edge case to the spec and regenerate; the spec becomes the living contract.
One result surprised us. We tried to specialize the model through fine-tuning — supervised, rejection sampling, DPO, self-distillation. None beat the plain base model with the retry loop. The diversity of sampling a general model proved more valuable than specialization.
Conjure does not eliminate every dependency. Frameworks, database drivers, and C extensions stay, and existing tools still earn their keep there. It targets the other half of the tree — the pure-logic utility code — where the supply-chain attack surface drops to zero because there is nothing left to attack.
Cite this work
@article{latentnode2026conjure, title = {Conjure: Replacing Library Dependencies with LLM-Generated, Verified Code}, author = {{Latent Node}}, year = {2026}, note = {Independent Research by Latent Node. Preprint}, url = {https://conjure.pages.dev} }